
跳槽准备之力扣算法

跳槽准备之力扣算法
李阳一、算法思想
1. 摩尔投票法
摩尔投票算法(Moore’s Voting Algorithm)是一种用于在数组中寻找多数元素的有效方法。所谓多数元素,是指在数组中出现次数超过一半以上的元素。最经典的例子就是用于众数的寻找。
摩尔投票算法的基本思想很简单,它通过消除不同元素之间的对抗来找到可能的多数元素。算法遍历数组并维护两个变量:候选元素和其对应的票数。开始时,候选元素为空,票数为0。然后对于数组中的每个元素,执行以下步骤:
- 如果票数为0,将当前元素设为候选元素,并将票数设置为1。
- 如果当前元素等于候选元素,则票数加1。
- 如果当前元素不等于候选元素,则票数减1。
这样做的效果是,相同元素的票数会相互抵消,不同元素的对抗也会导致票数减少。由于多数元素的出现次数超过一半以上,所以最终留下的候选元素就很有可能是多数元素。
遍历完整个数组后,候选元素即为多数元素的候选者。然后我们需要进一步验证候选元素是否真的是多数元素,因为可能存在没有多数元素的情况。我们再次遍历数组,统计候选元素的出现次数,如果发现它的出现次数超过了一半以上,则确认它为多数元素;否则,表示没有多数元素。
2. 贪心
贪心算法(又称贪婪算法)是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,算法得到的是在某种意义上的局部最优解 。
贪心算法不是对所有问题都能得到体最优解,关键是整贪心策略的选择
贪心算法一般按如下步骤进行:
①建立数学模型来描述问题 。
②把求解的问题分成若干个子问题 。
③对每个子问题求解,得到子问题的局部最优解 。
④把子问题的解局部最优解合成原来解问题的一个解
二、面试150道
2021年的某一天我怀着憧憬进入大学校园,我励志一定要好好学习。那时候室友推荐了力扣这个平台。室友说要成为编程高手必先刷算法题
于是我打开了力扣第一题两数之和…迄今已经过去了四年我再也没有刷过算法题。两数之和也成为一道印象深刻的一道题
有人相爱,有人夜里开车看海,有人leetcode第一题都做不出来。
拖延了四年发现我还是大傻逼
88. 合并两个数组
给你两个按 非递减顺序排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。
请你 合并nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。
**注意:**最终,合并后数组不应由函数返回,而是存储在数组 nums1 中。为了应对这种情况,nums1 的初始长度为 m + n,其中前 m 个元素表示应合并的元素,后 n 个元素为 0 ,应忽略。nums2 的长度为 n 。
示例 1:
输入:nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3 |
示例 2:
输入:nums1 = [1], m = 1, nums2 = [], n = 0 |
题解
class Solution { |
思路:
- 从尾部添加数组元素更加方便一些。
- 数组1中的末尾元素等于数组2与数组元素1中的较大者
- 当数组1元素为0时需要将数组2中的所有元素添加到数组1中
27. 移除元素
给你一个数组 nums 和一个值 val,你需要原地 移除所有数值等于 val 的元素。元素的顺序可能发生改变。然后返回 nums 中与 val 不同的元素的数量。
假设 nums 中不等于 val 的元素数量为 k,要通过此题,您需要执行以下操作:
- 更改
nums数组,使nums的前k个元素包含不等于val的元素。nums的其余元素和nums的大小并不重要。 - 返回
k。
示例 1:
输入:nums = [3,2,2,3], val = 3 |
示例 2:
输入:nums = [0,1,2,2,3,0,4,2], val = 2 |
题解:
class Solution { |
简单题拿下拿下!虽然脑子很乱不过也是独立思考完成了哈哈 李阳,我知道你不会复习!
26. 删除有序数组中的重复项
李阳你就是大傻逼,没有思想的东西,只会抄答案,最简单的也不会做…给你一个 非严格递增排列 的数组 nums ,请你 原地]删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。然后返回 nums 中唯一元素的个数。
考虑 nums 的唯一元素的数量为 k。去重后,返回唯一元素的数量 k。
nums 的前 k 个元素应包含 排序后 的唯一数字。下标 k - 1 之后的剩余元素可以忽略。
示例 1:
输入:nums = [1,1,2] |
示例 2:
输入:nums = [0,0,1,1,1,2,2,3,3,4] |
题解
class Solution { |
啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊 日了狗了,这么简单没想到 当快指针元素不等于慢指针元素时,将值复制给慢指针,并且++,返回长度+1的数值
169. 多数元素
给定一个大小为 n 的数组 nums ,返回其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。
你可以假设数组是非空的,并且给定的数组总是存在多数元素。
示例 1:
输入:nums = [3,2,3] |
示例 2:
输入:nums = [2,2,1,1,1,2,2] |
题解:
class Solution { |
- 通过一个计数器
count初始化出现数量为1,初始化maj为数组首元素。 - 遍历数组:若当前元素与
maj相同,count++;不同就count--; - 当
count == 0时,将当前元素设为新的maj,并重置count = 1(因为当前元素是新候选者,至少出现一次)。 - 最终
maj就是多数元素。
示例验证(以 nums = [2,2,1,1,1,2,2] 为例) |
世界上怎么会有如此精妙的算法
189. 轮转数组
给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。
示例 1:
输入: nums = [1,2,3,4,5,6,7], k = 3 |
示例 2:
输入:nums = [-1,-100,3,99], k = 2 |
题解
class Solution { |
太他妈妙了… ….
121.买股票的最佳时机
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
示例 1:
输入:[7,1,5,3,6,4] |
示例 2:
输入:prices = [7,6,4,3,1] |
题解
class Solution { |
hhhhh复习写出来啦
122. 买股票的最佳时机2
给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。
在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。然而,你可以在 同一天 多次买卖该股票,但要确保你持有的股票不超过一股。
返回 你能获得的 最大 利润 。
示例 1:
输入:prices = [7,1,5,3,6,4] |
示例 2:
输入:prices = [1,2,3,4,5] |
示例 3:
输入:prices = [7,6,4,3,1] |
题解
贪心和暴力求解有啥区别
class Solution { |
55.跳跃游戏
给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。
示例 1:
输入:nums = [2,3,1,1,4] |
示例 2:
输入:nums = [3,2,1,0,4] |
啊啊啊啊啊啊啊啊啊啊啊啊啊啊好难。第一遍就超时了
题解
class Solution { |
45.跳跃游戏2
给定一个长度为 n 的 0 索引整数数组 nums。初始位置在下标 0。
每个元素 nums[i] 表示从索引 i 向后跳转的最大长度。换句话说,如果你在索引 i 处,你可以跳转到任意 (i + j) 处:
0 <= j <= nums[i]且i + j < n
返回到达 n - 1 的最小跳跃次数。测试用例保证可以到达 n - 1。
示例 1:
输入: nums = [2,3,1,1,4] |
示例 2:
输入: nums = [2,3,0,1,4] |
题解
- 你站在数组的第 0 个位置(起点),要跳到最后一个位置(终点,下标是 n-1)。
- 数组里每个元素 nums [i] 是 “权限”:比如 nums [0] = 2,说明你在位置 0 时,最多能往后跳 2 步(可以跳 1 步到位置 1,也能直接跳 2 步到位置 2)。
- 跳的时候不能超出数组范围,而且题目保证一定能跳到终点,不用考虑跳不到的情况。
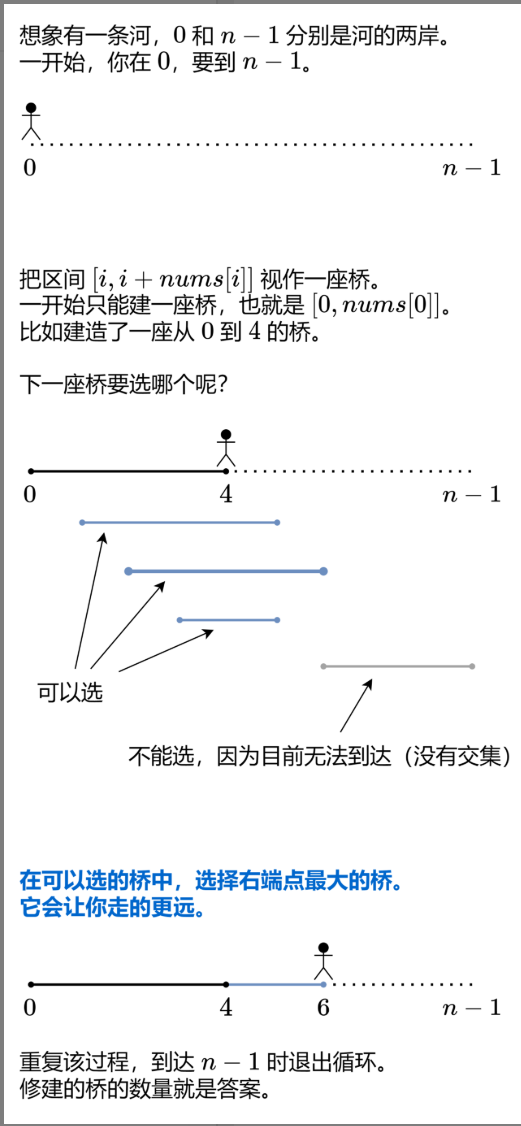
class Solution { |
头昏昏的啥都看不懂
我是大傻逼
247. H指数
翻译:数组中有h个不小于h的值,求最大的h
给你一个整数数组 citations ,其中 citations[i] 表示研究者的第 i 篇论文被引用的次数。计算并返回该研究者的 h 指数。
根据维基百科上 h 指数的定义:h 代表“高引用次数” ,一名科研人员的 h 指数 是指他(她)至少发表了 h 篇论文,并且 至少 有 h 篇论文被引用次数大于等于 h 。如果 h 有多种可能的值,h 指数 是其中最大的那个。
示例 1:
输入:citations = [3,0,6,1,5] |
示例 2:
输入:citations = [1,3,1] |
题解
class Solution { |




